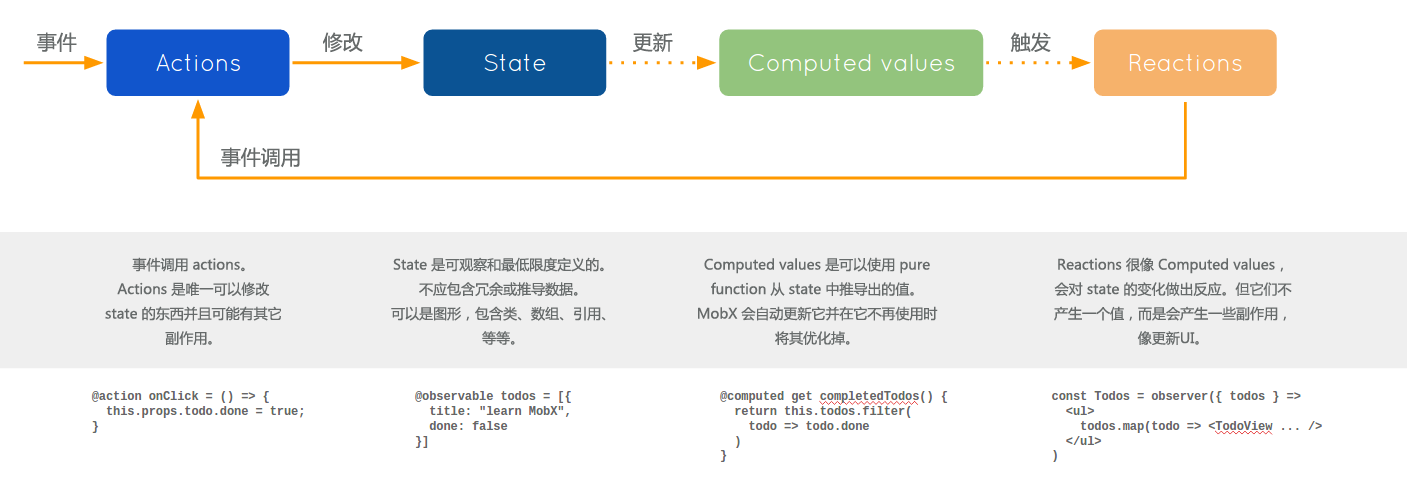
最近在拉勾教育上学习了一个专栏《14 讲提升职场竞争力》,感觉对个人职业发展很有帮助,特总结于此。学完这部分,你会从更高维度去思考问题,当别人还在依赖于直觉、经验做决策的时候,你已经从思维层面考虑到更多可能性和更完整全面的解决方案。
模块二,工作能力。 我会教你如何修炼语言表达能力、书面写作能力和职场学习能力。通过这些能力的修炼,你不仅能够把自己的工作结果最大化地展现出来,而且,依托强大的学习能力,你能及时更新自己知识体系和思维工具,不断迎接新的挑战。
其次,我会带你超越工作技能的维度,从行业知识和商业思维的角度,帮你建立一个完整的工作能力框架。这样你在职场中,就不会只是一个纯粹的执行者,你还有丰富的行业和商业能力储备,无论是做一个非常基础的工作,还是负责一条完整的业务线,你都有能力胜任。
模块三,人际合作。 这个部分我会介绍职场上真正有价值的人际关系该是什么样的,带你建立正确的经营职场人际关系的思维,学习职场人际关系建立与经营的方法技巧。
思维致胜 流程意识 所谓流程思维,简单地说,就是在解决问题的时候,你会不会想到从流程出发来考虑和解决问题。
使用流程 应用流程的工作场景也有强场景和弱场景之分。
优化流程 优化流程一般指的是对既有的流程进行改造。
如产品上线的流程 原来的流程:产品开发——测试——运维部署——开发上线——产品(人员)验收。
制定流程 你要负责一个项目或者一项业务,制定流程的能力是带领项目或者业务突围的必备条件。
如何学会制定流程? 确认关键节点 关键节点是一个最有目的性或者有关键产出物的环节。 确认关键节点的过程,就是理清事情的头绪或者关键操作的过程。
梳理逻辑关系 确认了关键节点后,接下来就要找到节点事件或者操作要点之间的逻辑关系,用箭头表示出前后的顺序关系。
细化完整流程 以上两步虽然表明了不同节点之间的逻辑关系,但只是一个粗线条的流程,只适合某些岗位在某些场景下的工作。
数据至上 在做汇报时,需要用数据增强你的职场说服力。
什么是数据思维 数据思维,简单来说就是在分析问题、做决策、汇报工作等关键工作场景中,依靠数据说话。
如何成为运用数据思维的高手 成为一个善于运用数据的高手,我认为你至少要在四个方面展开数据思维的修炼:
锻炼数据的敏感性 对外界、对自己多使用数据,培养对数据非常敏感,看任何问题,都会基于数据体现来考虑。
数据至上 所谓数据至上,就是任何事情,能用数据,就不用文字。 你需要在问题分析的时候、在执行落地的时候、在呈现结果的时候保持数据至上的意识。
追求精确 运用数据的时候要时刻保持精确性,因为精确能够体现你的专业性。
善用对比。 俗话说,没有对比就没有伤害,在数据应用方面,没有对比就不知道好坏。
复盘技巧 复盘其实是一个围棋术语,也称 “复局”,指的是“对局”完毕后,回顾推演这一盘棋的记录,以检查下棋的过程中招法的优劣与得失关键。把复盘放到工作中来说,就是通过剖析工作全貌,把其中每个局部拿出来进行仔细分析,以萃取核心工作经验与价值。
工作总结≠工作复盘 总结是对结果好坏的分析,而复盘是对产生结果原因的深度分析。如果复盘中缺乏对于原因的深度剖析,就起不到复盘应该有的作用。
复盘各方的收益 对公司而言,复盘为公司积累了处理相关领域的宝贵经验,一次投入多重收益;
工作深度复盘的三步骤 梳理事情的完整过程和信息 在进行一项工作复盘的时候,首先要对事件的过程和信息进行完整的梳理。因为在做一件工作的时候,基于协作等因素,信息分散在不同的人和角落中。把这些信息进行系统的汇总,你对整件事情才会有完整的认知,复盘才会更全面。否则,信息的缺失,让你的复盘工作可能根本没法往下进行。
深度剖析重要节点和事件 复盘第二步就需要剖析重要的节点事件,从中寻找这些重要事件进展过程中存在的问题。这里可以从事和人两个层面入手。
总结重要的经验教训 在第二步的复盘中,你一定会分析出大量有价值的经验信息,但它们过于庞杂且相对孤立,这样的经验你即使总结出来,可能在下次遇到问题的时候也很难复用。
复盘注意的两个注意要点 第一,不断发问。 为了达到深度复盘的目的,你需要不断地发问,在不断追问中找到问题的核心,提炼出有价值的经验教训。
拆解方法 拆解思维,指的是把一个问题拆分成颗粒度更细的维度,从更细小的组成部分考虑和分析问题,从而找到解决方案的一种思维。
用拆解思维解决难题困境 方案规划类问题的破解之道 方案规划类问题往往需要通过 PPT 呈现解决方案,所以也可以叫 PPT 类问题。大到公司的战略规划、年度业务规划,小到个人的工作汇报、产品规划、用户调研方案等都属于此类问题。
数据计算类问题的破解之道 数据计算类问题,指的是以严格的数据考核的工作问题,比如销售目标的拆解、投资回报率的计算、用户量的增长等诸如此类的问题。
数据计算类问题的破解之道步骤 第一步:找到基本公式。销售单价,但这个问题中求解的是会员收入问题,所以,公式需要进行相应的改造。 会员价格。
流程梳理类问题及其破解之道 流程梳理类问题,指的是问题解决环节之间具有前后密切承继关系的问题。
优先思维 对工作区分优先级, 区分工作的优先级(先做什么后做什么)
四象限法则 详细拆解四象限法则,破解不会用优先级思维的困境1
2
3
4
5
重要
*
不紧急----*----紧急
*
不重要
四象限法则判断事情优先级 先判断事情的紧迫性和重要性 紧迫性主要是从时间维度上来评估,一件事情到底紧迫与否,就看离最终的时间节点的远近,如果截止日期迫在眉睫,那么就非常紧迫,反之紧迫性就没有那么高。
能力重识(六大核心职场力) 语言表达(教你清晰表达,高效沟通) 破解“不愿说” 不敢说、不屑说
摆脱“说不好” 在职场中,有一类人自信十足,他们并不怵说话,但你听他们的话总是感觉云里雾里、一团乱麻、没有重点,怎么也理不清。
最佳表达(金字塔原理 16 字箴言) 结论先行、以上统下、归类分组、逻辑递进。
开头一句话抛出观点或者概括核心内容 最好用一句话提纲挈领,抓住听讲者的注意力。
中间用一二三明确分层 当你抛出观点或者总括内容之后,马上就要进入细节的内容。如果你是发表观点,那么马上就要说明你的理由。如果是分析问题,那么就展开现象、原因和解决办法。在说的时候,你应该注意两点。
明确分层:把你所讲述的细节内容要点分清一二三,因为人类的耳朵天然不擅长处理结构化的信息,耳朵在接受信息的时候,听到的往往是线性的信息。 说话节奏:在需要停顿的时候进行停顿,该强调的一定要突出语调,对于信息的不同层次,结合第一、第二这样明显的分界标志词说出来,让他们听到你的结构,减轻听讲者的负担。结尾重复总结核心内容 为了防止参会的人听完后面的信息忘了前面的观点,所以在讲完时要总结,再强调下你的观点。否则,参会的人可能会进行选择性理解,这样就会导致沟通偏差。走出“说不破” 跟前面“说不出”正好相反的人,便是“话匣子”。他们的话不缺乏逻辑层次,在一些简单的问题上,也能发表一些让人耳目一新的观点。走出“说不破”的解决办法 没有从问题出发,一定要时刻以问题为原点,跳出信息的海洋,用最精简的信息来回答问题。 没有研究透问题,还有些同学在发表观点的时候,倒是不会出现“失焦”的情况。但是,可能对问题没有研究透,聊到的都是一些皮毛的东西,也会出现说不到点子上的困境。书面表达 职场中的书面表达能力 我们以职场中最为常见的 3 种书面表达能力——公文、PPT 和业务文案写作能力,来展开这个话题。公文写作能力 公文写作能力,又叫作格式化文本的写作能力。例如邮件的写作、简历写作、会议纪要、会议邀请通知、投标书等都属于此类。这些文案的写作通常都有特定的格式和话语体系,强调逻辑性,不强调艺术性,写作时中规中矩。PPT 写作能力 PPT 是职场中使用非常广泛的一种工具,在工作汇报、会议演讲中都会用到。构图精致、画面优美、动画适宜的 PPT 很容易吸引别人的注意力,且同样会影响他人对你个人的认知。 从整体上,所有的 PPT 页面应该是围绕着一件事情或者一个观点展开的,每一页都是对核心观点的阐释。这点听起来简单,但现实中却存在很多反例,缺陷与不足之处各异。 从局部来说,每一页 PPT 也都需要有一个核心观点,并有相应的论证。 具体到每一页 PPT ,标题都应该是对本页内容的核心概括,是总论点之下的一个分论点,而其中的内容无论是文字、图片,还是数字图表,其实都是支撑论点的论据。业务文案写作能力 业务文案的写作并不是每个职场人都会遇到的工作,但是,很多业务类岗位的职场人都需要具备这种能力。以运营人员为例,需要写的活动文案和短信文案以及 Push 文案都会有较大的差异,必须深入理解这些文案的写作特点和差异,才能产出符合业务特性的文案。如何修炼自己的书面表达能力 掌握第一要诀——写 对于任何人来说,要进行书面表达能力地修炼,其实没有什么捷径可走,窍门就是写。 修炼逻辑能力 职场上的写作核心目的是信息沟通、说服别人,所以逻辑性是职场写作最重要的要求。比如,你要通过邮件说服别人支持你的工作,或者说服上级接受你的方案,不能只讲道理,没有证据。也不能观点和理由混杂在一起,这样是不行的。
通过模仿快速掌握基本的写作方法 当职场中遇到需要写作的场合,而又不知道如何写的时候,最快速的解决办法就是模仿他人的写作方法来先完成任务。之后,再考虑长期训练相应能力的问题。
职场学习 职场学习和学校的学习有很大的不同,其中最关键的一个就是:学校学习的是知识,职场学习的是能力。
职场上学习步骤 执行能力 当一个人处于基础执行层时,最核心的就是把工作任务搞定的能力。这时候,你承担得更多的是一些具体的落地工作,虽然这些事情中也需要你思考一些细枝末节问题的合理性,但是,主要还是领导规划你来执行。
研究能力 所谓的研究能力,就是面对问题,分析清楚问题的本质,找到问题出现的深层原因,基于原因寻找可靠的解决办法。
综合能力 你要承担起一个管理者的角色,你要突破的是综合能力。因为你要管理几个人来完成工作任务,你不仅要学会规划的能力(规划事情的能力和人员安排的能力),而且要学习管理人的能力。此外,因为你不仅要和上级领导相处,你还要和下级、同级的其他管理者相处,你处在了夹心层,要处理各种各样的关系,你要学习人际管理的方法。
你该如何修炼执行能力和研究能力? 从执行能力到研究能力的学习,其实是从硬技能到软技能的学习。所谓硬技能,就像产品经理的需求文档撰写能力、画原型图的能力,这些侧重于解决具体问题的能力。而软技能,就像这门课程中工作思维的学习。
如何练就硬核的执行能力 第一种区分:通用性能力和专业性能力 所谓通用性能力,就是那些在解决任何具体问题的时候都可能用到的能力,它们的普适性比较强,比如第二模块中讲到的语言、书面表达能力,行业视野和商业思维,都是通用性的工作能力。
第二种区分:操作性能力和指导性能力 所谓操作性能力,就是那种具有明确的操作方法,你按照具体的操作方法反复练习就可以掌握的能力。比如 Excel 技能、活动运营的操作流程、需求文档撰写能力等。
工作技能 很多同学进入一个岗位,日复一日干着重复的工作,节奏堪比钟表一样,一眼就可以望到头。这种无望却无奈的困境,以前存在于很多传统企业中,现在已经遍及互联网大厂。
如何摆脱“螺丝钉”困局? 寻找高增长的行业和企业 快速发展的企业,规模会不断扩大,人员规模也就需要同等扩大,这时候就会让你有机会扩大自己的工作技能(内部转岗)。
建立“π 型能力”结构 关于职场人的能力,以往其实有一种说法,叫作“T 型能力”,就是一横一竖,一横指的是你要在职业能力的横向方面向广博修炼,一竖指的是你要在专业能力的纵向方面向精深修炼。“T型能力”是过去人们常常津津乐道的一个指导原则。
行业视野 概括来说,与你所在企业相关的行业有关的一切知识和信息,都属于这个范畴。
行业视野三个层次 最高层:主要是对企业生存所依存的政治、经济、法律、技术、社会环境的认知,这是行业的宏观层认知。 中间层:主要是对企业生存所依赖的上游、中游和下游环境的认知,这是行业的中观层认知。 最底层:主要是对企业自身生存的价值创造的完整链条的认知,这是行业的微观层认知。宏观层认知及其修炼 你要有行业视野,首先你要有宏观层的认知,这意味着你要有意识去了解大的政策、经济、环境、技术和社会环境,也就是你要进行企业环境的 PESTEL 分析。中观层认知及其修炼 中观层的认知,主要是了解行业内的协作和制约关系,要对此形成认识,可以进行行业的产业链分析。产业链具体如何梳理呢? 第一步,明确角色。根据普适性的商业逻辑,产业链一般又可以具化为上游供应商、中间渠道商、下游服务商、终端消费者 4 类主要的角色。微观层认知及其修炼 产销服具体化 这种方法的核心逻辑就是,根据生产、销售、服务这三个关键环节,看企业对于在各个环节中设置了哪些具体的活动,它们形成的前后协作关系,就构成了企业核心价值链。组织架构逆推 企业的组织架构都是严格按照价值创造活动而来,所以,逆向去看组织架构就可以非常清楚地看到企业的价值创造活动。弄清它们之间的协作关系,就弄清了企业的价值链。业务关系链梳理 所谓业务关系链梳理法,就是以你的岗位为基点,梳理和你协作的上下游同事关系,以及他们的上下游关系,梳理后整个完整的业务流程就是价值链。商业思维 所谓商业思维,简单地说,就是思考企业为达到利润目标,所需要关注的最核心的经营环节是如何运转的。该如何掌握基本的商业思维? 职场人身处在企业中,多少都会有一些商业方面的知识,但是,要对此有深入的了解,你至少要系统地了解六个方面的内容。用户需求 在互联网企业中,需求是一个高频的词汇。你可能经常听到产品经理说我这有个 XX 需求……但是,他们说的需求其实仅仅是一个产品功能点。而我这里的需求指的是企业生存发展的根本立足点——用户需要什么。市场概况 市场概况主要包括行业的现状、竞争的情况、市场规模大小。有用户需求只能说明这个市场存在理论上的可能,但是,市场概况则能够直观地说明这个市场的现实可能性。解决方案 解决方案,简单来说就是通过什么方式或者产品解决用户的需求,解决方案通常包括你要解决用户的哪一部分具体需求,具体通过什么产品形式来解决。商业模式 商业模式,主要指的企业通过什么盈利。日常最常见的商业模式,就是提供商品获取附加值。比如三只松鼠的干果,或者提供服务收服务费,比如理发。资源需求 一个企业在做任何一个产品项目的时候,都需要相应的资源需求配置,具体说就是要配置多少人,要花多少钱。风险情况 风险,就是任何可能给企业造成冲击的不确定因素,或者给企业造成经营困难的事情。企业遇到的风险,很可能就是你遇到的风险,这是具有高度相关性的。比如很多新闻资讯类 App 因为内容不合规问题被下架,不仅对企业是风险,对于具体的相关人也是风险。人际历练 关系建立 人际关系方面你至少要处理好“一主两辅”三种关系 和直接领导的相互关系——主要的人际关系; 和本部门同事的协作关系——第一种辅助的人际关系; 和非本部门同事的合作关系——第二种辅助的人际关系。和上级领导建立积极的“互信和支持”关系 职场中,和领导建立强互信关系,获得领导的信任和支持,你才能拿到重要的机会、产出成果、做出业绩、升职加薪。互信关系 所谓互信就是你要让领导信任你,你也要信任领导。领导信任你的前提是你要对他忠诚,这样他才真正放心你,给你委以重任。如果一个曾经背叛过其他领导先例的人,给到任何一个新领导,他都很难对这个人产生信任。相互支持关系 所谓相互支持关系,也是一种双向的关系,首先你要支持领导,支持他的业务规划,支持他的分工安排,支持他的日常工作安排。和部门同事建立良性的“竞争中的协作”关系 部门同事的关系相对比较特殊、敏感,既有竞争也有协作,是一种竞争中的协作关系。这里的重点是竞争,其次才是协作,它们是有先后顺序的。所以,你在和同事相处的时候,要处理好这对矛盾的关系。职场中的竞争关系 在同一个部门中存在着广泛的竞争:关于资源的竞争、关于工作任务的竞争、关于领导关注度的竞争,还有如果领导有一天高升,可能还会面临空缺职位升迁的竞争。职场中的协作关系 在协作方面,你和同事应该建立的是一种什么样的关系呢?我认为是一种平等互助的协作关系。要建立这种关系,你就要学会不要侵犯领地、不要越俎代庖、不要给别人当老师。和支持部门同事建立“长期互利”的合作关系 职场中,要做出工作成果,除了同部门同事之间的协作配合之外,还要处理好和其他支撑部门同事的关系,要和他们建立“长期互利”的合作关系。所谓长期互利关系,指的是你要尽可能和其他部门同事建立相对稳定、给彼此都带来职场成长或收获的关系。互利的合作关系 之所以要建立互利的关系,是因为大家都有各自的绩效目标和升职加薪的年终目标,如果别人帮你的工作总是没有成果,那么,你觉得他还会有信心再支持你吗?尤其是他长达半年一年支持你的工作,最终无所成果,绩效很差,那么他很可能就不会再和你合作了。关系经营 如何主动和领导建立深入的“互信和支持”关系 要做主动的关系管理 主动和领导沟通,通过重要事件与领导进行深度沟通互动,以此让领导了解你的积极态度,验证你的工作能力,感受你的忠诚与信任。要以专业性让领导信服 在互联网的职场中,要和领导建立互信的关系,最重要的就是靠实力,所谓实力既包括工作思维和能力,也包括工作成绩。而后者其实也是取决于前者的。关键时刻顶得上去 如何在关键时刻顶得上去,你至少可以有两个思路:勇于攻坚克难、勇于承担责任。不要给领导创造“惊喜” 领导处于高位,天然会有不安全感,你一定要照顾他这种需求。在日常的工作中,多注意自己的言行可能给领导造成误解和困惑。你重点要关注两个点。该怎样和同事建立良好的合作或协作关系 建立广泛的同盟 之所以要建立广泛的同盟,从大的方面来说还是要服务于自己职业发展的各种目标,尽可能减少工作的阻力,尽可能增加你开展工作的顺利性,给自己营造一个做事的良好外部环境。保持开放的心态 所谓保持开放心态,就是你在面对和处理同事关系的时候,要自信不封闭,学会将心比心,求同存异。以职业性打动对方 和同事建立良好的合作或者协作关系的核心基础是你的职业性,就是上一讲课程中讲到的要以理服人、以能服人、以成果服人。 PS:以职业性打动对方也有一个负面清单,就是千万不要以领导压人。有些人遇到事情推动不下去,就拿领导说事,企图逼迫别人就范,这实际上在证明自己的无能,只能让别人对你心生厌恶。当然,有的时候遇到一些油盐不进,就是喜欢讲道理的人,可以适当、委婉的借助于领导的权威加速事情的推进,但是,注意掌握分寸。
以工作成果回馈对方 以成果回馈对方,指的是你和别人的合作,应该建立在有成果的工作产出基础之上。这就对你提出了较高的要求,意味着你在做任何事情的时候,都尽可能以有所产出为出发点来考虑问题,因为如果别人支持你的事情要总是没有成果,他们也受不了,因为他的领导也会拷问他的工作成果,他的工作绩效,部分的取决于你的工作成果。
沟通说服 要做到的这一点,我认为至少要解决三个问题:
让对方了解你的意图; 让对方同意你的观点和方案; 让对方支持你的行动。 下面我就从沟通前、沟通中、沟通后三个环节,跟你聊一聊如何更好地和别人沟通,获得他们实际的支持行动。
沟通前:有目的地设计沟通策略 一定要在沟通之前做充分的准备,不要赤手空拳去沟通,否则结果惨不忍睹。
基于同步信息的沟通 如果你只是同步信息,那么你要传递什么信息,一定要清楚、明确,不能模糊和模棱两可。
选择沟通方式 如果是不重要的信息,你通过书面还是面对面都可以,怎么方便怎么来。 如果是重要简短的信息,那么,你可以通过微信或者口头表述的方式沟通即可。 如果是重要复杂的信息,你就需要采取相对正式的书面方式,比如邮件来和对方沟通,如果书面沟通无法完全表达清楚,那么就补充面对面会议沟通。 你沟通的信息,别人是否成功接受了,你一定要确认。 基于达成共识的沟通 如果你是要达成共识,那么,你要做的准备工作就更多了,你要根据问题的性质、沟通的对象、行动计划等因素,综合考虑该怎么尽快地达成自己的目的。
沟通中:妥善管理沟通对象和环境 职场中的沟通,会有各种各样的情景,很多时候都是有业绩压力和利益争执的情景。这时候人的行为、语言、情绪、行为都会偏离日常状态。如果你是沟通的发起人,一定要注意对沟通情景的设计和管理。
沟通环境方面的设计管理 如果你预计是这个沟通可能会有激烈的交锋,或者各种不太和谐的情况发生,那么,你就可以在沟通的环境因素方案有所考虑,比如你可以定一个大一点的会议室,或者比较敞亮的会议室。可以在开场的时候,准备一些暖场的笑话之类的。尽可能创造一个相对弱化紧张氛围的环境。
沟通对象方面的设计管理 当然,对于环境的设计其实能做的事情不多,主要还是对人的方面的管理。其中又包括对于他人的管理和对自己的管理。
沟通后:总结复盘获取多重价值 当你结束一次和领导的讨论,或者和同事的一次脑暴之后,你应该立即着手记录你们讨论中彼此主要的观点,存在的核心问题,等待解决的问题。否则,这些信息内容会随着时间消逝,在你的大脑中逐渐变模糊,这样就影响了后面问题的解决。
]]>